


MENU
MENU
BK21플러스 웹진VOL.16

곽 노 준 교수
서울대학교 융합과학부 BK21 플러스 스마트 휴머니티 융합사업단 단장
알파고가 우리 사회에 충격을 몰고 온 지도 벌써 2년이 지났다. 2016년 3월 알파고사건 이후 인공지능 및 딥러닝이라는 키워드는 학계 뿐 아니라 일반인들 사이에도 유행이 되고 있다. 본고에서는 인공지능 기술들의 현황을 살펴보고 인공지능 기술의 발달과 더불어 미래사회가 어떻게 변화할지에 대한 필자의 생각을 정리해 보고자 한다. 인류는 아주 오랜 옛날부터 사물을 의인화하는 습성이 있었고 사물이 사람처럼 생각하고 사람과 소통하며 사람과 같은 판단을 할 수 있다면 어떤 일이 일어날지에 대한 수많은 상상을 해 왔다. 이러한 상상들을 바탕으로 사물에 지능을 부여하는 인공지능에 대한 연구가 시작되었다.
초기의 인공지능은 사람이 정한 일정한 규칙에 따라 자동으로 동작하는 자동기계인 오토마타에 대한 연구로부터 시작되어 점차 주어진 규칙에 따라 동작하는 것이 아니라 과거에 얻은 데이터를 기계가 학습하게 함으로써 새로운 규칙을 기계가 생성하고 이에 따라 작동하도록 하는 기계학습에 관한 연구로 발전하였다. 이러한 기계학습 분야의 초기 연구로 1940년대부터 생물의 신경망을 논리회로로 모델링 하고자 하는 연구를 들 수 있다. 그 후 1957년 인공신경망을 이용해 영상을 인식하고자 하는 목적으로 퍼셉트론 (perceptron) 이라는 알고리즘이 개발되었고, 1986년 Rumelhart 등은 퍼셉트론을 여러 층으로 쌓아서 입출력간의 관계를 학습할 수 있도록 한 다층 퍼셉트론(multi-layer perceptron)이라는 구조와 이를 경사 하강법(gradient descent)을 통해 학습하는 역전파(back-propagation) 알고리즘을 개발함으로써 인공신경망의 첫번째 붐을 이끌었으며, 이러한 기반 위에 2006년 이후로 최근 많은 사람들의 입에 오르내리며, 알파고의 성공을 이끌어낸 한 축이기도 한, 신경망의 층을 매우 깊게 쌓아서 학습을 수행하는 딥러닝 기술이 엄청난 속도로 발전하고 있다. 딥러닝을 포함한 기계학습 알고리즘들은 크게 해결하고자 하는 문제에 대한 데이터와 더불어 그 데이터에 대한 정답을 알려주고 이를 학습하여 새로운 데이터에 대해 답을 유추토록 하는 지도학습, 주어진 데이터의 분포를 학습하여 데이터의 차원을 줄이거나 유효한 특징을 추출하는 비지도학습, 에이전트라고 칭하는 동작의 주체가 주어진 환경에서 동작을 해 가면서 간헐적으로 얻는 보상을 바탕으로 학습을 수행하는 강화학습 등으로 나눌 수 있다.

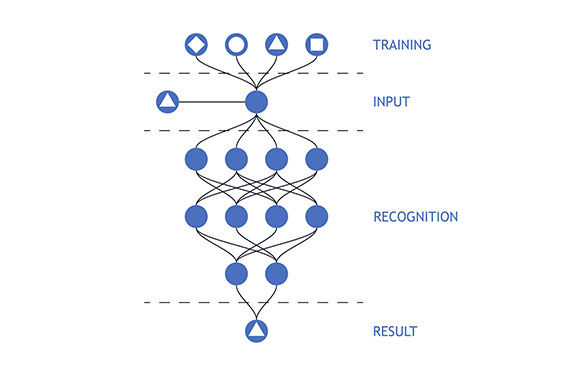
인공 신경망의 층을 매우 깊게 쌓아서 학습을 수행하는 딥러닝 기술이 엄청난 속도로 발전하고 있다.
이 중 지도학습의 대표적인 예로 영상이 주어졌을 때 영상이 무슨 영상인지 분류하는 영상 분류 문제를 들 수 있는데 컨볼루션 신경망을 바탕으로 하는 알렉스넷이 2012년 대용량 데이터셋에 대한 영상 분류 문제인 이미지넷 챌린지에서 기존 방법들보다 현저히 높은 성능을 보임으로써 딥러닝에 관한 폭발적인 관심과 연구를 이끌었으며, 2015년 이미지넷 챌린지에서는 마이크로소프트의 Resnet이 인간을 뛰어넘은 성능으로 우승하기까지에 이르렀다. 지도학습 방법의 대표적인 예로 영상분류 문제뿐만 아니라 주어진 영상에서 관심있는 물체의 위치와 종류를 파악하는 물체검출 문제도 들 수 있다. 물체검출은 특히 자율주행자동차에서 자동차 주위의 사람이나 자동차, 자전거 등 움직이는 물체, 신호등, 횡단보도, 교통표지판 등을 검출하고 이의 종류를 알아내는 용도로 활발히 연구되고 있다. 일반적으로 딥네트웍의 성능은 깊이가 깊어질수록 좋아지나 그에 따른 계산량의 증가로 자동차나 그 외의 제품에 내장되어 사용하기에는 속도가 너무 느리다는 단점이 있다. 이를 극복하기 위해 단순반복적인 계산을 빠르게 수행할 수 있는 GPU (graphics processing unit)를 적극 활용하거나 큰 네트웍의 성능은 어느정도 유지하면서 네트웍의 크기를 줄이기 위한 시도들도 활발히 연구되고 있다. 이외 영상에서 지도학습의 대표적인 예로 물체의 외곽선을 추출해내는 영상세그멘테이션, 영상에서 사람의 자세를 추정하는 포즈추측, 동영상에서 물체를 계속 추적하는 물체추적, 동영상의 종류를 알아내는 동영상 분류 등에 관한 연구도 딥러닝을 활용하여 활발히 진행되고 있다.


딥러닝 지도학습의 대표적 사례인 물체검출. 사람이나 자동차, 자전거 등 움직이는 물체 등의 종류를 알아낼 수 있다.
영상 분야 뿐만 아니라 음성 분석이나 자연어 처리 분야에도 지도학습이 성공적으로 적용된 사례가 많이 있다. 이 분야에서는 주로 순환신경망 (recurrent neural network)이 많이 사용되는데 이는 과거의 출력이 다시 되먹임되어 현재의 입력으로 동작하게 함으로써 네트웍을 학습하는 구조이다. 현재 독자들도 느끼는 바일테지만 대용량 데이터에 기반한 딥네트웍의 학습을 통해 음성인식의 성능이 획기적으로 높아졌으며 자동번역과 같은 자연어처리 문제들도 단어내재화 (word embedding) 기법과 순환신경망의 발전에 기반하여 비교적 만족할만한 수준의 성능에 도달하였다. 이렇게 높아진 영상 및 자연어처리 성능을 활용하여 최근 영상을 분석하여 얻을 수 있는 정보를 문장으로 나타내는 이미지캡셔닝 문제나 중고등학교 과학 교과서 등에서 흔히 볼 수있는 도표와 이를 설명하는 문장 등을 활용하여 주어진 문제에 적절한 답을 찾는 Textbook Q&A문제 등도 아직 초기 단계이나 활발한 연구가 진행되고 있다.
다음으로 최근 딥러닝을 활용한 비지도 학습의 대표적인 방법들을 살펴보도록 한다. 앞서 간단히 설명한 바와 같이 비지도학습은 주어진 데이터의 분포를 학습함으로써 주어진 데이터보다 줄어든 차원의 특징을 추출하거나 이를 활용해 사람이 보기 좋게 데이터를 일목요연하게 보여주는 비주얼라이제이션 등에 활용할 수 있다. 비지도학습을 통해 데이터의 분포를 알 수 있기 때문에 새로운 가상의 데이터를 생성하는 것도 가능하며 특히 이렇게 데이터를 생성하는 연구는 최근 딥러닝의 가장 뜨거운 연구분야 중 하나이다. 이 중 대표적인 연구로 GAN (generative adversarial network)을 들 수 있다. GAN의 생성자 (generator)에서는 불규칙 잡음(random noise)으로부터 가상의 데이터를 생성하며 분류자 (discriminator)에서는 실제 데이터와 생성자가 생산한 가상 데이터를 분류하도록 한다. GAN에서 생성자의 학습은 분류자를 잘 속일 수 있도록 즉 가상의 데이터와 진짜 데이터를 분류자가 구분할 수 없도록 진행되며 분류자는 가짜와 진짜를 잘 구분할 수 있는 방향으로 학습한다. GAN을 통해 사람의 얼굴 등 몇몇 대상에서는 사람이 진짜와 가짜를 구분하지 못할 정도의 가상 데이터를 생성할 수 있고 잡음과 더불어 제한조건을 생성자의 입력으로 인가함으로써 눈의 크기, 귀의 모양 등 생성하는 데이터의 특성을 사람이 조절하는 것도 가능하다. 이러한 기술에 힘입어 모짜르트 스타일의 음악이나 고흐 스타일의 미술 작품을 생성하는 것도 가능해졌다.


AI가 램브란트와 고흐의 화풍을 모방하여 그린 그림
마지막으로 작년 이래로 기계학습 분야의 가장 뜨거운 연구 분야인 강화 학습에 대해 간단히 소개하도록 한다. 강화학습에서는 로봇과 같은 에이전트가 환경에서 동작하면서 동작에 따른 이따금의 보상을 강화하는 방향으로 학습이 진행되며 특히 바둑이나 게임과 같이 동작 영역 (action space)이 유한한 분야에서 성공적으로 적용되고 있다. 강화학습은 모든 데이터에 대한 정답이 달려 있는 지도학습과 달리 가끔마다 한 번씩 주어지는 보상을 통해 학습을 수행해야 하므로 학습이 불안정하고 매번 학습할 때마다 편차가 크다는 문제가 있는데 이를 해결하기 위한 많은 방안들이 연구되고 있다. 특히 강화학습에서 전통적으로 사용되던 반복가치평가 (value iteration) 방법인 Q-learning과 영상에서의 컨볼루션 신경망을 결합한 DQN (Deep Q-network)을 통해 알파고가 프로기사들을 연거푸 이길 수 있었으며 간단한 Atari 게임들에서 사람보다 나은 점수를 얻고 있다. 하지만 반복가치평가 방법이나 정책 경사법(policy gradient)에서는 근본적으로 현재 상태와 동작에 대한 기대 가치에 대한 평가가 이루어져야 하는데 로봇 제어나 자동차 주행 등과 같은 실제 강화학습 문제에서는 가치에 대한 명확한 정의가 이루어질 수 없으므로 사람의 동작이나 이전 전문가의 동작을 모사하는 모사학습 (imitation learning)이나 보상함수를 추정하고자 하는 역강화학습 (inverse reinforcement learning) 등에 대한 연구도 활발히 이루어지고 있다. 최근 강화학습 방법인 DQN이나 역강화학습 방법을 이용해서 자율주행을 구현하려는 시도들이 많이 이루어지고 있으며 제품 디자인 등에 강화학습을 활용하는 성공적인 사례들이 쌓이고 있다.
이와 같은 인공지능 특히 딥러닝 기술의 발달에 힘입어 향후 다양한 분야에서 인류의 삶이 혁신적으로 바뀔 것으로 예상할 수 있다. 먼저 물체검출, 물체추적 기술의 발달과 강화학습, 향상된 지도 데이터의 적용으로 인해 향후 10년 이내에 골목길을 제외한 포장도로에서 완전한 자율주행이 가능해질 것으로 예상되며, 음성인식, 자연어 처리 기술의 발달로 인한 키보드 없는 컴퓨터 등 전자제품의 입출력 인터페이스의 획기적 변혁을 예상할 수 있다. 이미지 캡셔닝 기술의 발달로 자연어를 이용한 영상검색 및 자동일기 생성, 중국 충칭에서 이미 실험되고 있듯 얼굴인식 기술의 발달로 인한 범죄없는 사회도 조만간 우리 앞에 모습을 드러낼 것이다. 인공지능 기술과 대용량 데이터의 결합으로 인해 많은 사람들이 예측하듯 사용자 맞춤 금융, 법률, 교육 시스템 등이 소개될 것이고 많은 전문직이 더 이상 전문직이 아닌 사회가 출현할 것이다. 이 외에도 필자는 인공지능의 발달로 인해 가까운 미래에 우리가 현재 상상할 수 없는 변혁이 반드시 일어나리라 예상한다. 현재 미국, 유럽, 중국 등 전세계적으로 많은 젊은 정상급 인재들이 인공지능의 매력에 빠져 이 분야 연구에 뛰어들고 있으며 이에 따라 하루가 다르게 빠른 속도로 기술발전이 이루어지고 있다. 국내 인공지능 연구진도 세계적인 연구의 흐름에 뒤쳐지지 않는 수준의 연구성과를 이어가고 있으나 더 많은 인재들이 인류의 삶을 근본적으로 바꿀 이 분야에 뛰어들어 본인의 가치를 증명해 보일 수 있기를 바란다.